Building Coordinate Descent for Lasso Loss from Scratch
Introduction to the Lasso loss, and the math behind coordinate descent in the Lasso loss. Showing how the Lasso loss can be used to perform feature selection.
Building Coordinate Descent for Lasso Loss from Scratch
Many times when working with data in machine learning, we do not know before hand which features are the most important. This is especially true in situations where we have a large number of features. In this post I go over Lasso loss, which is a loss function that can be used to perform feature selection, and how to optimize the weights of the Lasso loss using coordinate descent.
What is Lasso loss
Before going over the function for Lasso loss, let’s first go over the mean squared error (MSE):
The Lasso loss is a regularized version of the MSE. It adds a penalty term to the MSE, which penalizes the model if it tries to use too many features.
Where is a hyperparameter that controls how much we want to penalize the model for using too many features.
Coordinate Descent for Lasso Loss
Our goal here is the same as in the polynomial or linear regression case: we want to find the weights that minimize the Lasso loss. However, we notice that we can’t use the gradient descent algorithm because the penalizing term is not differentiable at 0!
So instead of going over all the weights at the same time, we can optimize one weight at a time while keeping the others fixed. This is called coordinate descent.
The basic idea goes like this:
-
Initialize the weights to 0.
-
For each weight, find the value that minimizes the Lasso loss while keeping the other weights fixed. This is a one-dimensional optimization problem, which can be solved using a simple line search.
-
Repeat step 2 until convergence.
So let’s calculate how to update the weights for linear regression!
Coordinate Descent for Linear Regression
Here’s basic model for linear regression:
Thus when we plug it to our Lasso loss, we get:
Here we used small trick to make the derivative of the MSE part easier to compute. We divided the MSE part by 1/2, because , thus dividing it by 2 we get , which is simpler to work with.
Coordinate Setup
We need to optimize this loss function one weight at a time, by putting all other weights to be constant.
For a given weight , we can define the estimate as:
Thus the error for the -th sample is:
But from this we notice, that the is constant for a given , so we can define:
This is called as residual, and it is the part of the target that is not explained by the other weights. Using residual in our error equation we get:
Finally we can use this in our loss function, where goal is to minimize the error.
We can differentiate the quadratic part of the function. Let’s define it as
From here we can define two variables (to ease computations):
So our function becomes
Handling the Lasso Penalty Term
However, as we know, there is also the lasso penalty term that needs to be taken care of in the lasso loss. As the is the penalty term, it’s derivate is not defined in !
However, we can use the subgradient of the absolute value function, which is defined as:
Thus the whole subgradient function becomes:
Now we can try to find the optimal by setting subgradient to zero:
and from this we can get the optimal w!
Soft-Thresholding Function
We already have our optimal , but we must take care of the sign function.
Let’s first notice how the function behaves for different values.
- , thus the update is
An in order to make sure that we need to have .
- , thus the update is
For this to be negative we need to have .
OK, so from the positive and negative cases, we know when they hold. But there is also the case In that zone, neither the positive and negative case holds, and giving value to contradicts the arguments! So only viable option is to set .
Putting all these together we get:
From this we can define soft-thresholding function
Where and This can also be put to single-formula version:
Thus our final function becomes:
Using soft-thresholding function in Python
Now that we know the math behind the coordinate descent, we can start implementing it in Python!
Let’s again start by generating data and initializing the variables:
import numpy as np
np.random.seed(42)
n_samples, n_features = 200, 10
X = np.random.randn(n_samples, n_features)
true_w = np.zeros(n_features)
true_w[0] = 2.0
true_w[3] = -1.5
true_w[7] = 3.0
y = X @ true_w + 0.5 * np.random.randn(n_samples)
N = len(y)Then we define the training and test set from this data
train_ratio = 0.8 # Train-Test Split Ratio
train_size = int(N * train_ratio)
indices = np.random.permutation(N)
train_idx, test_idx = indices[:train_size], indices[train_size:]
X_train, y_train = X[train_idx], y[train_idx]
X_test, y_test = X[test_idx], y[test_idx]In this example, I use linear regression and MSE, like in the math section of this post. I also define here the soft-thresholding function which is the key part of the coordinate descent algorithm.
def model(X, weights):
return X @ weights
def mse(y_true, y_pred):
return np.mean((y_true - y_pred)**2)
def soft_thresholding(x, alpha):
return np.sign(x)* np.maximum(np.abs(x) - alpha, 0)Finally we can define our coordinate descent function:
def coordinate_descent_lasso(X, y, alpha = 0.1, max_iter = 10000, tol = 1e-6):
w = np.zeros(n_features)
for _ in range(max_iter):
w_old = w.copy()
for j in range(n_features):
residual = y - X.dot(w)
rho_j = X[:, j].dot(residual)
z_j = np.sum(X[:, j]**2)
w[j] = soft_thresholding(rho_j, alpha * train_size) / z_j
if np.linalg.norm(w - w_old) < tol:
break
return w
w_estimated = coordinate_descent_lasso(X_train, y_train, alpha = 0.1, max_iter = 10000, tol = 1e-6)
print("Estimated weights:",w_estimated)Let’s stop here for a moment to analyze the code.
The algorithm itself is quite similar to the gradient descent, we both have iteration over the data and we update the weights. However, in this case, we do the update one feature at a time.
, and are defined as same as in the math section. And the update rule is the soft-thresholding function, is also the same:
Model Evaluation
Finally, we can check the results of our model, and see if it does the feature selection correctly.
| Parameter | Value |
|---|---|
| Estimated weights | [ 0.90319841, -0, -0, -0.8026248, 0, 0, 0, 1.36803295, -0.12094796, -0 ] |
| Test MSE | 4.376614616021284 |
| Test R² Score | 0.6883895004659537 |
As we can see, the model actually put most of the irrelevant features to zero. Also the relevant features have similar behaviour in weights as in the true model.
But we notice that the weights are actually smaller than the one in the true model.
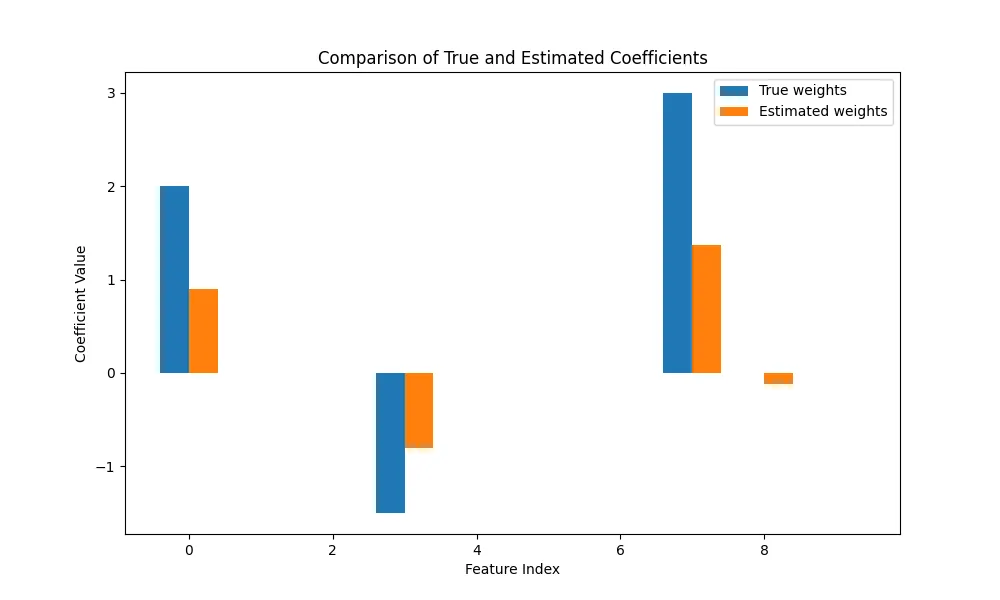
This is common charactericstic of Lasso regression, as Lasso adds penalty to the loss function, it also forces the the estimated coefficient closer to zero. This means that coefficient tend to be smaller in absolute value than the true coefficient.
However, given that MSE and R² score are reasonable, this result is generally good from predictive standpoint. It shows that even though the coefficients are biased, the model overall captures the relationship in the data well.
Summary
In this post I went through the math behind the Lasso loss and how it can be calculated using Coordinate descent. After that I implemented the Lasso regression from Scratch using python, which helped us to select the relevant features from the data.
For the full code, check out the Github repository. Thanks for reading! :)